이번 6주 차 포스팅에서는 요즘 AI Art 커뮤니티를 뜨겁게 달구고 있는 Wan2.2, 그리고 새롭게 출시된 ideogram의 캐릭터 기능을 살펴보도록 하겠다.
[목차여기]
일단 간략한 소개부터:
WAN2.2 오픈소스 버전 출시 및 ComfyUI Day 0 네이티브 지원 (25.07.28)
WAN2.2 오픈소스 버전 출시 및 ComfyUI Day 0 네이티브 지원 | ComfyUI Wiki
WAN 팀이 혁신적인 MoE 아키텍처를 적용한 Wan2.2 오픈소스 버전을 공식 출시했습니다. 이로써 영상 생성 품질이 크게 향상되었으며, ComfyUI는 Day 0부터 네이티브 지원을 제공하여 사용자가 최신 영
comfyui-wiki.com
Alibaba에서 개발한 '오픈소스' 비디오 생성 모델이다.
오픈소스 출시 이후 AI 커뮤니티에 Wan2.2로 생성한 이미지와 영상들이 도배되기 시작하였다. (비디오 생성 모델인데 이미지가 어떻게 가능한 것인지는 표 아래에 설명해 두겠다.)
+ 벌써부터 많은 사람들로부터 Black Forest Labs에서 최근 출시한 Flux Krea보다도 뛰어나다는 의견들이 나오고 있다.
| Wan 2.2 14B T2V (GGUF Q8) vs Flux.1 Dev (GGUF Q8) | text2img | "WAN 2.2 is superior undoubtedly coz it feels so realistic and cinematic where as Flux generations have that AI polished look." / "Wan is much better. I hope someone trains wan to be more aesthetically pleasing and stylistically diverse." |
| While as a video model it's not as special, WAN 2.2 is THE best text2image model by a landslide | "WAN 2.2 EXCELS at t2i to the point I can't go back to Flux or even Chroma. the textures are perfect, details are intricate af and the censorship is minimal unlike Flux." |
| Wan 2.2 human image generation is very good. This open model is the best! | "What's better is as far as i know wan produced amazing results and training is more effortless compared to flux. Flux is stubborn to train ..." |
| Flux Krea Comparisons & Guide! | "Tried it out and while it is better than Flux Dev for sure, using Wan 2.2 as an image generator is superior IMO." |
| Limitations of T2I WAN 2.2 | "People are also not saying 'WAN can do T2I like a bonus', they are saying WAN is better than flux, chroma for T2I." |
| You can use WAN 2.2 as an Upscaler/Refiner | "I have been testing my Flux model as a refiner for WAN 2.2 as I like the skin detail more." |
Flux를 넘을 수 있는 것이 나올까 싶었는데, 중국이 이걸 해냈다는 것처럼 보인다.
뒤에서 서술하겠지만, 난 그렇다고 믿지 않는다.

Sora를 제외하면 중국회사끼리 경쟁하고 있다. VEO가 비교군에서 빠진 이유는 중국에서 구글에 대해 강력한 제한을 두고 있기 때문이라고 추측해 볼 수 있다. 반면 OpenAI의 Sora의 경우 워낙 비디오 생성 AI의 시조 느낌이다 보니 억지로 넣어놓은 것이 아닐까 싶다.
*참고로 WAN2.2는 '비디오 생성 모델'이다. 그러니 이걸로 이미지를 생성했다는 사례들은 비디오 프레임을 1 프레임으로 설정하여 이미지처럼 뽑았다는 것일 뿐이다. 이런 식으로 TI2V를 TI2I로도 쓸 수 있다.
Ideogram Character (25.07.29)
Ideogram Character
The first character consistency model that works with just one reference image. Now available to all users for free on ideogram.ai and the iOS app!
about.ideogram.ai
내가 지난 첫 번째 포스팅에서 영문 타이포 디자인 쪽으로 약간 숭배(?)에 가까운 평가를 내렸었던 Ideogram에서 출시한 신기능이다.
겉으로 보기에는 이게 Flux kontext와 하나도 다를 것이 없어 보일 수 있는데, 한 발짝 조금 더 나아간 기능이 갖춰져있기는 하다.

정말 말 그대로 Further, '더 나아간' 커스터마이징 기능이다.
그래서 테스트를 진행해 보고 과연 그 기능이 얼마나 뛰어난지 알아보고자 한다.
테스트 진행:
Wan2.2 - Wan2.2-TI2V-5B (TI2V : Txt&Img to Vid)
나는 Comfyui에서 테스트를 진행하였다.
설치방법은 매우 간단하다. (이제 그냥 comfyui 설치 자체가 cmd 작업 없이 원클릭으로도 가능하게끔 간편해졌다.)
Manager에서 Comfyui를 최신 버전으로 업데이트한 후, Workflow > Browse Templates에 들어가 Video 카테고리에서 Wan2.2 모델을 선택 후 다운받으라는 것들 하나씩 다운로드하면 끝이다.
만약 업데이트를 해도 반영이 안 된다면, 재설치하는 것을 추천한다. 그렇다고 이전 파일들을 따로 백업하거나 지울 필요는 없다. 새로 설치하는 컴피 폴더로 이전 데이터를 자동으로 긁어올 수 있기 때문이다.

참고로 난 RTX 3080을 사용 중이다. 14B가 아닌 5B로 가볍게 테스트한 것은 내 컴퓨터 GPU의 한계 때문이니, 만약 당신의 컴퓨터 사양이 나보다 훨씬 뛰어나고 더 높은 퀄리티의 결과물을 원한다면 14B를 직접 사용해 보길 바란다.
참고로 3080 스펙으로는 5B에서 10초 영상을 뽑는 것도 GPU 메모리 부족이 뜬다. 따라서 나는 5초로만 뽑겠다.
컴피가 없는 사람은 웹에서 찍먹정도만 해보는 것도 나쁘지 않을 것이다.
웹사이트 주소: https://wan.video/
[week2-2] AI API 플랫폼과 서버리스 (+Mirage 소개)
이번 2주 차 2번째 포스팅은 지난 한 주를 보내면서 문득 든 의문에 대한 답을 찾는 과정을 기록해보자 한다. (요즘 n8n 공부를 해보려고 하는데, 이건 나중에 다뤄보겠다) 그전에 내가 첫 포스팅
mapsycoy.tistory.com
그리고 내가 전에 2주 차 두 번째 포스팅에서 소개한 OpenArt에서도 쓸 수 있다!

워크플로우를 실행하면 위와 같이 화면이 뜰 것이다.
자세히 보면 CLIP Text Encode (Negative Prompt)가 중국어로 쓰여있는데, 이걸 알아보기 쉽게 영문으로 바꾼다는 등의 행위는 하지 않는 것이 좋을 것이다. 애초에 중국어 위주로 학습되어 있기에 타 언어에는 반영이 잘 안 될 수도 있다.
순서대로 한국어로 번역하면 다음과 같은 내용이다.
색조가 화려함 / 과다 노출 / 정적임 / 세부 묘사가 흐릿함 / 자막 / 스타일 / 작품 / 회화 / 화면 / 정지된 상태 / 전체적으로 회색빛 / 최악의 품질 / 저화질 / JPEG 압축 흔적 / 추함 / 불완전함 / 여분의 손가락 / 잘못 그려진 손 / 잘못 그려진 얼굴 / 기형적임 / 외관 손상 / 기형적인 팔다리 / 손가락이 붙음 / 움직이지 않는 화면 / 어수선한 배경 / 세 다리 / 배경에 사람이 많음 / 거꾸로 걷기
나는 별다른 수정 없이 위 부정 프롬프트 그대로 사용하기로 하였다.
테스트 이미지 및 프롬프트는 다음과 같다.

이 이미지는 내가 전에 제작해 둔 '인도 타지마할 앞에서 전통복장을 입고 있는 레오파드 게코 도마뱀과 기타를 들고 있는 귀뚜라미'의 모습이다.
해당 이미지를 테스트용으로 선택한 이유는 Kling 2.1 / Seedance / Veo2 / Hailuo 02 4가지 툴 모두 좋은 퀄리티의 결과물을 뽑지 못했었기 때문이다.
제 아무리 강력한 비디오 생성 모델이라 하더라도, 실사가 아닌 3D, 그냥 3D가 아닌 인형 재질, 사람이 아닌 동물, 포유류가 아닌 파충류 그리고 곤충의 단계로 넘어가는 순간부터는 고장 나기 시작한다. 왜냐하면 그만큼 학습 데이터가 부족하기 때문이다.

Kling 2.1은 가장 자연스러운 움직임을 보였지만 중간중간 노이즈가 섞이다가 아예 캐릭터 일관성을 잃었고, Seedance는 움직임이 많이 약하고, Veo2는 춤이라기에는 움직임이 부자연스러웠으며, Hailuo 02는 전반적으로 모든 부분에서 다 떨어졌다.
물론 이건 최악의 결과물들만 모아놓은 것이고, Kling 2.1과 Seedance의 경우 괜찮게 뽑힌 것도 꽤 있었다.
이제 테스트 결과를 공개하겠다.

역시나 이상하게 나왔다. (*참고로 립싱크 기능이 해당 워크플로우에 없을뿐더러, 인간 얼굴이 아니면 그 어떤 툴에서도 제대로 립싱크가 적용되지 않는다.)
이 테스트 취지는 새로 나온 AI의 한계를 파악하는 것이기에 나름 성공적인(?) 결과라 볼 수 있겠다만, 실드를 좀 쳐보자면.. 일단 14B가 아닌 5B라는 가벼운 모델이 사용되기도 하였고, 거기에 더해 도마뱀이나 귀뚜라미에 대한 학습 데이터 부족이 가장 큰 원인이라고 생각하므로, 여기서 캐릭터가 [게코 도마뱀 > 다람쥐]나 [귀뚜라미 > 토끼]와 같은 소형 포유류로 바뀌기만 해도 훨씬 나은 결과물이 나올 것이다.
Video posted by floopers966
civitai.com
실제로 그 두 캐릭터로 만들어진 결과물이 커뮤니티 상에 존재하여 이 또한 공유해 본다.
+GPU 한계로 인해 웹에서도 동일한 프롬프트로 한번 더 진행해 보았다.

웹에서 기본으로 제공해 주는 10 크레딧을 소모하여 뽑았으니, 14B 성능의 GPU가 사용되었을 것이라 예상한다.
과연 결과는 어떨까?

이전 컴피에서 작업한 것보다 동작은 훨씬 자연스러워졌으나, 이빨이 마치 공룡처럼 변했다.
위에서 언급한 학습 데이터 부족이 주원인일 것이다. 왜냐하면 실제 게코 도마뱀은 이빨이 100개가 넘고, 또 사람 눈에는 잘 보이지 않을 정도로 작고 조밀하게 자라있다. gecko라는 키워드를 제대로 인식 못하길래 그냥 lizard라 입력한 것인데, 무슨 코모도왕도마뱀처럼 만들어놨다.
*사람형 이미지는 웬만하면 결과가 잘 나올 것이 뻔하기 때문에 따로 테스트를 진행하지는 않겠다.
Ideogram Character (img2img)
이것도 마찬가지로 그냥 사람으로 하면 너무 뻔하고 재미없으니 게코 도마뱀 캐릭터로 진행해 보겠다.

일단 캐릭터를 업로드하였는데, 자동 마스킹 상태부터가 영 좋지 못한 것이 불안하다.

나는 기본적으로 제공되는 The Superhero Template을 선택하였다. 템플릿을 선택하면, 위처럼 자동으로 장문의 프롬프트를 생성해 준다. (*원래부터 ideogram이 자동으로 프롬프트를 생성해주기는 한다.)
아래는 자동으로 생성해 준 프롬프트 내용이다.
A comic book-style illustration of a superhero flying through an urban cityscape at sunset. The superhero wears a sleek black and metallic blue suit with a glowing yellow emblem on the chest. The suit features a distinctive crown-like design on the head and flowing cape that extends upward. The superhero's pose shows them in a dynamic flying position with arms extended forward. The background showcases a detailed cityscape with modern high-rise buildings, including glass and steel skyscrapers. The buildings are rendered in warm sunset colors with golden lighting. The streets below are filled with small dots of traffic. The overall color palette consists of deep blues, metallic blacks, golden yellows, and warm sunset tones. The illustration has a high-contrast, dramatic style typical of superhero comic books, with strong shadows and highlights on the costume and buildings. The composition places the superhero in the center of the frame, flying diagonally across the image from bottom right to top left.
일단 프롬프트 상에는 원본 캐릭터 생김새에 대한 내용은 전혀 없다. 그렇다면 과연 결과는 어떻게 나올까?
원본 이미지 상에 꼬리가 없으니 그것은 절대 구현할리 없겠지만, 그래도 얼굴만이라도 정말로 내가 꿈꾸는 슈퍼 히어로 게코의 모습으로 탄생할 수 있을까?

아.. 혹시나 했는데, 역시나 '완전히' 실패하고 말았다.
음, 그렇다면 조금만 난이도를 낮춰서 3D 애니메이션 속 사람 캐릭터 얼굴은 어떨까?
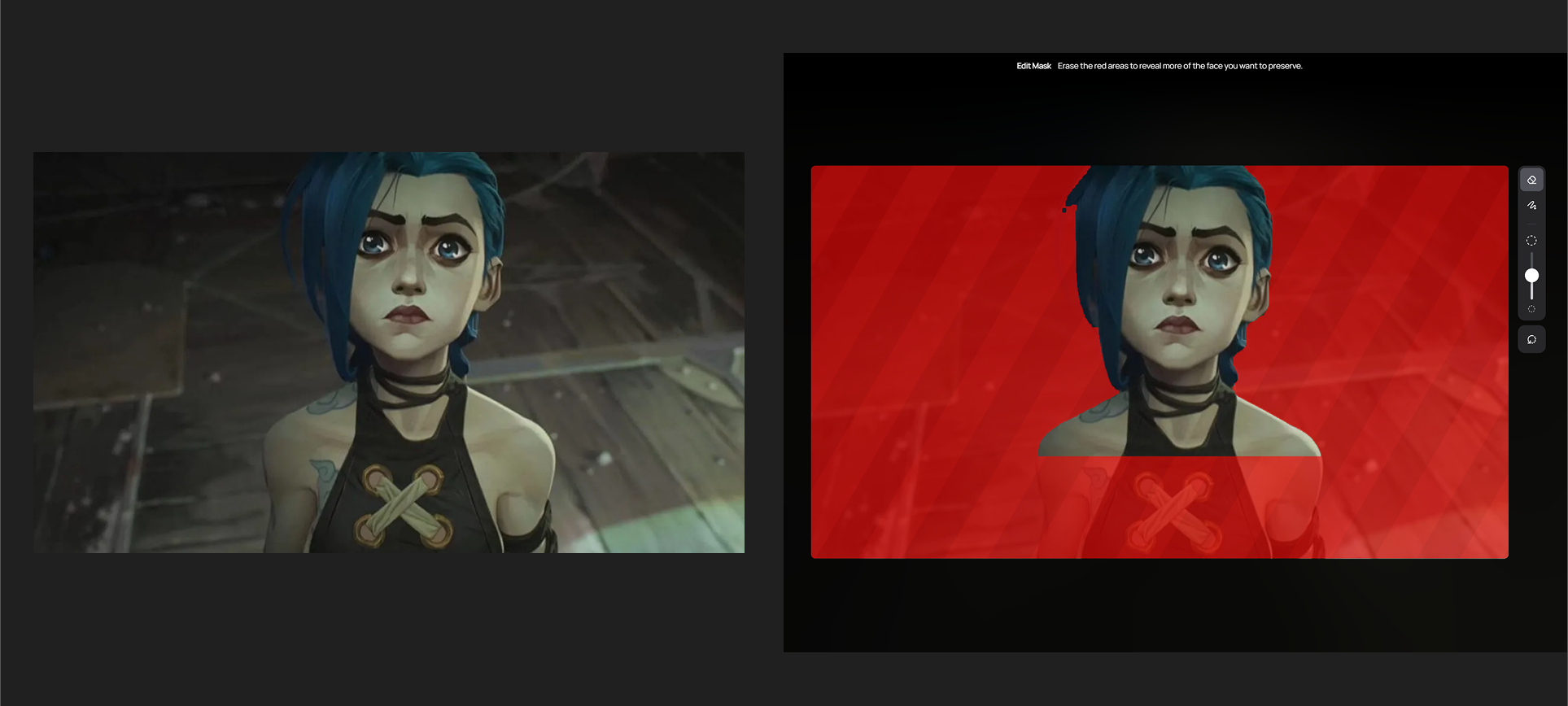
아까 전 도마뱀 캐릭터보다는 마스킹이 훨씬 깔끔하게 따진 것으로 봐서 조금 기대가 된다.
다시 마찬가지로 동일한 The Superhero 템플릿을 선택하였다. 자동 생성 프롬프트 내용은 동일하다. (*템플릿마다 프롬프트가 지정되어 있는 것 같다.)
과연 이번에는 결과가 어떻게 나올 것인가?

음, 이것도 실패다.
템플릿 스타일이 문제일 수도 있겠다.
따라서 이번에는 템플릿을 사용하지 않고 직접 프롬프팅을 해보겠다.
얼굴은 잘 살렸지만, 아케인 특유의 2.5D 질감이 배경과 몸에 반영되지 않았다.

레오파드 게코도 마찬가지이다. 심지어 어깨깡패가 되었는데, 자세히 보면 승모근처럼 보이는 부분이 원본 팔이다;;
그나마 3번 이미지는 손 텍스처를 얼굴과 유사하게 만들어줬는데, 어쨌든 불만족스러운 결과이다.
이제 최대한 난이도를 낮춰서 픽사 애니메이션 캐릭터 [루카]를 사용해 보겠다.

예상대로 이건 학습데이터가 쌓여있어서 그런지 적용이 잘 된다. 그렇다고 Flux Kontext보다 뛰어난지는 잘 모르겠다.
그나저나 실사가 아닌 캐릭터들은 전부 어깨 가슴 부분까지 포함시켜 마스킹하던데, 이건 단순 기능적 오류인 건지.. 아니면 디포르메를 맞춰보겠다고 기능적으로 구현을 해둔 것인지.. 결과물이 그다지 좋지 않다 보니 영 알 수가 없다.
마지막으로, 앞서 소개했던 Further 커스터마이징 기능은 제대로 작동하는지 알아보겠다.
이번에는 일론 머스크의 사진으로 진행해 보았다.

기본 얼굴 마스킹(좌), 그리고 얼굴+모자 마스킹(우)을 비교해보고자 한다.
*참고로 얼굴 마스킹은 자동으로 마스킹을 생성해 준 그 상태 그대로 사용하였다. (제대로 얼굴만 크롭 했는지 확인하기 위함)

프롬프트는 둘 모두 사이버펑크 템플릿을 사용하였다. *young은 지웠다.
Photograph of ayoungperson in a vibrant cyberpunk city setting, expression of determined focus in the neon-lit streets, looking ahead with a confident and assertive posture. The background is a chaotic, yet beautiful, blend of holographic advertisements, towering skyscrapers, and flying vehicles. Rain streaks across the reflective surfaces, casting dynamic shadows and adding to the atmosphere. The outfit is futuristic with glowing accents. The contrast is stark with dark shadows and side lighting emanating from the neon street lights.
이제 결과를 확인해 보자.

위에 빨간 박스 테두리 표시가 얼굴+모자 마스킹 버전이고, 그 아래가 얼굴 마스킹 버전이다.
실사로 진행했음에도 불구하고 결과물의 퀄리티가 그다지 뛰어나다고 느껴지지는 않는다. 게다가 얼굴만 마스킹한 것도 결국 모자가 함께 생성된 것을 알 수 있다. 자동 마스킹 기능이 모자 등 액세서리를 완전히 지우지는 못하나 보다.
차이점이라면 아래는 모자에 세부 디테일이 없는 반면, 위에는 원본 모자에 적혀있던 글자가 그대로 반영되었다는 것이다.
전반적으로 꽤나 실망스러운 결과이다.
오늘의 결론
"뭐 더 나은 모델이 나왔다더라~ 엄청나다더라~"
그런 말들이 AI Art 커뮤니티에 자주 돈다.
그중에 몇몇은 광고성 글이겠지만, 실제로 그럴만한 퀄리티의 결과물들이 올라오니 혹하는 것은 사실이다.
허나, 사람들이 간과하는 것은 대부분의 고퀄리티 영상과 이미지들은 '실사에 가까운' 또는 지나치게 '인간 중심 편향'이라는 점이다.
인간들이 좋아하는 귀여운 '고양이', '강아지', '토끼', 그리고 '햄스터'와 같은 포유류 동물들은 구현이 쉽다.
마찬가지로 상상 속 크리쳐인 '드래곤', '고블린' 등도 다양한 게임/영화 매체에 등장할 정도로 인기가 많은 키워드이니 학습 데이터가 꽤 쌓여 구현이 쉽다. '2D 애니메', '픽사', '지브리', '사이버펑크', '스팀펑크' 같은 스타일도 똑같이 적용된다.
그러니.. 뭐든지 인간들이 많이 소비하는 인기 콘텐츠 위주로 돌아간다. 반면 비주류 문화는 철저히 무시되고 있다.
개똥철학일 수도 있지만, 이는 내가 남들처럼 한눈에 봐도 멋있거나 세련된 이미지를 가지고 테스트를 하지 않는 이유이기도 하다.
그런 이미지를 갖고 테스트를 진행하면 당연히 높은 확률로 좋은 결과가 나올 것이고, 다른 AI 유튜버들처럼 그것으로 어그로 썸네일 등을 만들어 더 많은 사람들을 유입시킬 수는 있겠지만, 진정한 본질은 그게 아니라는 거다.
니치(틈새) 주제 및 키워드로 테스트를 진행하는 순간, AI의 한계는 너무나도 빨리 명확하게 드러난다.
내 기준에서 이미지나 영상 생성형 모델의 발전은 FLUX.1과 Seedance에서 멈췄다.
왜 생성형 AI기업들은 서로 간에 벤치마킹은 그토록 열심히 하면서, 더 넓은 범위의 데이터를 학습시키려 하지 않는 것일까?
물론 비용이 많이 들고 수요가 지극히 적다는 것이 가장 큰 원인이겠지만, 그런 사각시대까지 포함해 차별화시킨다면 더 많은 사람들에게 도움이 될 수 있을 텐데 말이다.
+ 내용 추가 (08.27)
🍌나노바나나 출시 이후로 또 한 번 특이점이 왔다.
하지만 단지 퀄리티가 좋아진 것일 뿐, 데이터 부족 현상은 여전하다고 본다.
아래는 나노바나나가 생성해 준 픽사 스타일의 춤추는 레오파드 게코 캐릭터이다.

그러나 실제 레오파드 게코의 손가락 개수(5개)도 맞추지 못했을뿐더러, 꼬리를 너무 얇게 생성해 준다.
이걸 팩트기반으로 분석하면 해당 도마뱀의 건강 상태가 매우 좋지 못하다고 볼 수 있다.
그저 아쉬울 따름이다.
*썸네일 이미지 출처: https://docs.comfy.org/tutorials/video/wan/wan2_2
'생성형 AI' 카테고리의 다른 글
| [week9-2] Qwen-Image-Edit (FLUX.1 Kontext와 차이점) (0) | 2025.08.26 |
|---|---|
| [week7-2] NC AI (리니지 만든 그 NC 맞습니다) (0) | 2025.08.15 |
| [week5-2] 4가지 Bleeding 현상 (Poisoning/Distraction/Confusion/Clash) (0) | 2025.07.31 |
| [week4-2] 유럽권을 선도(?)하는 프랑스의 Mistral AI (0) | 2025.07.23 |
| [week4-1] Grok4 vs KIMI K2 (六小虎) (0) | 2025.07.21 |