이전 포스팅에서 나는 정부에서 추진 중인「독자 인공 지능 기초 모형 (AI 파운데이션 모델」경진대회에 대해 잠깐 언급했었다.
이 프로젝트는 글로벌 수준의 국가 대표 AI 모델을 개발하기 위한 대형 경진대회로, 과기정통부가 주관하고 있다.
총 15개 팀이 경쟁한 가운데, 지난 8월 초 5개 '정예팀'이 선정되었다. 그리고 이 중에는 'NC AI'도 포함되어 있다.
엔씨소프트의 NC AI가 이 5개 팀에 포함된 것은 업계에서 상당한 화제를 모았으며, 일부에서는 '예상외'라는 반응이 나왔다. 당연히 나도 처음에 이 소식을 듣고 놀랐다.
나는 엔씨가 리니지를 빼면 시체인 회사인 줄만 알고 있었는데, 이는 나의 무지함에서 비롯된 오판이었을 뿐, 실제로 엔씨소프트는 2011년 국내 게임사 중 최초로 AI 연구개발(R&D) 조직을 설립하며 AI 분야에 깊이 있게 투자했다더라..🫨
생각해보니 나는 2023년 엔씨가 유튜브에 올린 AI 모델 소개영상을 직접 봤었다.
지금은 해당 영상이 비공개 처리되어서 확인이 불가한데(대체 왜??), 그때 반응이 어땠냐면
"그런 기술로 제대로 된 게임이나 만들어라.", "그런다고 주식이 오르겠냐.", "게임 접고 이 사업이나 해라." 같이 비꼬는 댓글이 대부분이었다.
[컨콜] 엔씨, 아이온2의 긍정적인 평가 기대…7종 신작 준비중 : 게임샷
엔씨소프트는 12일 오전 2025년 2분기 실적발표 컨퍼런스콜을 진행했다.
www.gameshot.net
아무튼 내년에 아이온 2를 포함하여 무려 게임 7종을 순차적으로 선보일 예정이라고 한다.
이렇게만 놓고 보면 탈리니지 시도 및 사업을 다각화하기 위한 노력이 돋보여 실적이 많이 개선되었을 것 같지만, 실상은 그닥이다. 엔씨의 올해 2분기 매출은 3824억 원, 영업이익은 151억 원, 당기순손실은 360억 원으로, 한마디로 '적자'이다.
그렇다 보니 작년 물적 분할에 이어 올해에도 대규모 '인원 효율화'를 진행 중이라고 한다.
엔씨는 지난해 말부터 희망퇴직, 권고사직, 프로젝트 취소 등을 통해 약 1,000명 규모의 인력을 감축했으며, 25년 본사 인력을 3,000명 미만으로 줄이는 계획을 여전히 추진 중에 있다.
[단독]엔씨, 본사 아트 직군 우선 구조조정 착수..."연내 본사 인력 3000명 미만으로"
엔씨소프트가 자회사 루디우스게임즈가 제작하던 '택탄'의 개발을 중단한데 이어 본사 소속 아트 직군의 구조조정에 착수했다. 각 조직별로 희망퇴직 대상자로 선정된 일부 직원들에겐 지난주
news.mtn.co.kr
특히 아트 직군 우선 감축이라카더라.. (그래서 넥슨이 상반기에 대규모 채용을 했었구나 싶다.)
그렇다면 그 원인은 아무래도 AI의 영향이 크다라고 보는 것이 맞을 것 같다. 사실상 AI를 쓰면 7년 차 이상 시니어만 자리에 앉아 있으면 되지, 굳이 주니어를 둘 이유가 전혀 없긴 하다.
때문에 더더욱 이번 포스팅에서는 [NC AI]에 대해 알아보고자 한다.
[목차여기]
NC AI 컨소시엄
본격적으로 모델을 파헤쳐보기 전에 지난 11일 [NC AI 컨소시엄] 내용을 다룬 뉴스 스크립트 하나를 읽어보자.
카카오·KT 제치고 ‘국대 AI’ 도전… NC AI “산업에 특화된 소버린 AI 만들겠다” | 한국일보
엔씨소프트 자회사 NC AI가 국가대표 AI 기업으로 선정되며 네이버, LG와 경쟁합니다. NC AI는 170명 인력, 54개 기업 컨소시엄, 멀티모달 AI, 산업별 맞춤형 AI 개발 등 국내 AI 산업 혁신을 이끌고 있습
www.hankookilbo.com
카카오·KT 제치고 ‘국대 AI’ 도전… NC AI “산업에 특화된 소버린 AI 만들겠다”
위 제목 속 소버린 AI (Sovereign AI)는 우리 흔히 알고 있는 '자주국방'처럼 자주적인 'AI 주권'을 뜻한다.
해당 컨소시엄은 과기정통부에서 주관하는 K-AI 사업의 일부로 구성되었다.
세계적 수준의 자체 AI 파운데이션 모델을 만들어 미·중 AI 기술 종속에서 벗어나 제조·미디어 등 기간산업 혁신을 이끌어내는 것을 목표로 한단다.
글로벌 최고 성능 200B급 독자 대규모 언어 파운데이션 모델 패키지 개발, 독자 LLM 기반 통합 멀티모달 인지 생성 파운데이션 모델 패키지 개발, 독자 AI의 산업 확산을 지원하는 “도메인옵스(DomainOps)” 플랫폼 구축 및 서비스, 제조·유통·로봇·콘텐츠·공공 산업을 위한 산업 특화 파운데이션 모델 개발을 목표
출처 : 인공지능신문 - NC AI 컨소시엄, 독자 AI를 위한 최고의 국가대표... 54개 기관 ‘그랜드 컨소시엄’
당장은 코웃음 칠 수도 있는 목표이기는 한데.. 어 솔직히 나도 글로벌 최고까지는 모르겠다.
파라미터 수가 성능과 비례한다는 말도 이제 옛말이라고는 하지만 여전히 말이 많고, 200B를 웃도는 대규모 모델에는 그만큼 많은 비용이 들어가기에 성능 대비 정말 효율적인 것인지 아닌지도 뜯어보기 전까지는 모른다.
가장 최근에 나온 GPT-5도 사용된 파라미터 수가 공식적으로 밝혀지지 않았는데, 이게 적은 파라미터로 최대 효율성을 뽑아내었기 때문에 기술적인 부분에서 비공개를 유지 중인 것인지, 아니면 반대로 너무나도 많은 양의 파라미터가 사용되어 과도한 전력사용과 탄소배출로 환경에 악영향을 주고 있다는 안 좋은 이미지가 씌워질 것을 방지하기 위해 공개하지 않는 것인지 알 수가 없다.
나는 개인적으로 후자라고 생각하는 것이, Grok4에 사용된 파라미터 규모가 무려 1.7T이기 때문이다.
어쨌든 그렇기에 만약 NC AI가 개발한 LLM이 글로벌 빅테크 모델 Intelligence 지수 20위 안에만 든다고 해도 나는 대성공이라고 보는데... 여기서 잠깐!
당장 주목해야 할 놀라운 이슈!!

최근 5개 정예팀 중 무려 2개 팀, LG AI의 EXAONE, 그리고 업스테이지의 Solar는 Meta를 제치고 각각 글로벌 15위, 20위 안에 들었다는 점..!!
얘네들은 이미 소버린 AI에 한층 더 가까워진 상태이다.👏👏👏
*참고로 Solar는 그 순위가 이전 달에 비해서 낮아진 거다. 7월까지만 해도 전체 12위였는데... 그래도 여전히 20위 안에 머무르고 있다는 것이 대단하다.

참여 기업 및 기관 목록

| 주관 기관: NC AI | |
| 연구 개발 기관 (14개) | 수요기업 및 협력 기업 (40개사) |
| 한국전자통신연구원 (ETRI) | 포스코DX |
| AIWORKX (前Testworks) | 롯데이노베이트 |
| 한국과학기술원 (KAIST) | NHN |
| 서울대학교 | HL로보틱스 |
| 고려대학교 | 인터엑스 |
| 연세대학교 | 미디어젠 |
| · · · | MBC |
| - | · · · |
다른 기관 컨소시엄과 비교해 놓은 표가 있어 아래 첨부한다.

(어라 근데 한글과컴퓨터는.. 엔씨 대표가 예전에 공동 설립했던 회사[1] 아닌가?)
프로참석러인 KAIST가 LG 컨소시엄에만 참여 못한 것으로 보아, LG AI는 Only B2B인가 보다.
최근 엄청난 반도체 기술력을 자랑하며 메타로부터 1조 원이 넘는 인수 제안을 받았지만 거절한 퓨리오사AI가 LG AI에 붙은 이상, 최종 우승팀 중 하나는 이미 정해졌다고 본다.
그나저나 뤼튼이 LG에 붙은 건 그 속내가 너무 뻔히 보인다.
서비스 형태, 기술적 시너지 중 어느 것을 놓고 봐도 네이버나 NC가 더 어울리는 선택지일 텐데, 지드래곤이랑 제일기획한테 비싼 돈 주고 "뤼뤼뤼자로 시작하는~" 같은 그런 다소 질 낮은 광고를 찍어서 단기 매출만 끌어올리고 장기적인 브랜드 호감도는 급감시키는 뤼튼의 지난 행보를 보면 분명 LG와의 협력관계로 정치적이거나 금전적인 이점이 작용했을 것이라 예상해 본다. (왜냐면 지금 과기정통부 장관이 LG AI 출신[2]이다..🙄)
기관 별 특징
어쨌든 우리가 눈여겨봐야 할 것은 NC AI 컨소시엄 참여기관이니, 각각의 주력 서비스나 기술을 표로 정리해 보겠다.
| 참여 기관 | 주요 특징 |
| ETRI (한국전자통신연구원) |
AI 기술 표준화 및 기반 연구, 멀티모달 AI 개발, 데이터 신뢰성 기술 (KorBERT, EAGLE 개발) |
| KAIST (한국과학기술원) |
고급 AI 연구, 3D 비전 및 로보틱스 기술, LLM 고도화, 멀티모달 AI 지원 (BInD, MOFFUSION, MARIOH, Blockwise Parallel Decoding, DarkBERT, MetaVRain 개발) |
| 서울대학교 | AI 알고리즘 및 데이터 처리 전문, LLM 및 멀티모달 모델 연구 (Llama-Thunder, 한국형 의료 LLM, 인공지능 모델 편향성 감소 기술 개발) |
| 고려대학교 | 산업 적용 AI 연구, AI 알고리즘 개발, 데이터 처리 및 최적화 (KULLM, 도심 완전자율주행 모델 개발) |
| 연세대학교 | AI 윤리 및 안전성 연구, 데이터 구축 및 검증 기술 (AI 심리상담 챗봇 개발) |
| AIWORKX | AI 데이터셋 구축, 안전성 평가, 모델 검증 및 수학 문제 해결 데이터셋 개발 |
| 포스코DX | 제조 산업 AI 적용, 스마트 팩토리 솔루션, 데이터 기반 산업 혁신 (자체 sLLM, Smart Factory Platform, 포스코형 AI 에이전트 개발) |
| 롯데이노베이트 | 유통·서비스 AI 혁신, 소비재 AI 적용, 마케팅 및 운영 최적화 (Aimember 플랫폼) |
| HL로보틱스 | 로보틱스 및 자동화 기술, AI 기반 로봇 시스템 개발 (파키 개발) |
| 인터엑스 | 산업 데이터 구축 전문, AI 데이터 관리 및 처리 플랫폼 (GenX, Document AI, Gen.AI, Physical AI 개발) |
| 미디어젠 | 미디어·콘텐츠 AI 적용, 음성·영상 생성 및 편집 기술 (MIRAGE 개발) |
| MBC | 방송·미디어 콘텐츠 생성, AI 기반 콘텐츠 제작 및 배포 (방송영상 AI 학습용 데이터 구축) |
| NHN | 클라우드·IT 서비스 지원, AI 인프라 운영 및 확산 (AI EasyMaker, AI Human 개발) |
(솔직히 연구개발 성과로만 따지면, KAIST가 후보에서 밀려 나올 이유는 없어 보인다. 아무래도 기업이 아니다 보니 산업 적용성이 낮을 것이라는 판단 때문에 탈락한 것이 아닐까 싶다.)
위 참여 기관 서비스 목록을 보면 로보틱스(자동화·로봇 시스템)와 음성(음성 합성·콘텐츠 생성) 쪽이 상대적으로 두드러지게 많다는 점을 발견할 수 있다.
- 로보틱스 관련: HL로보틱스(로보틱스·자율주행), KAIST(3D 비전·로보틱스), 포스코 DX(스마트 팩토리 자동화), 인터엑스(디지털 트윈 기반 자동화) 등 4개 이상 기관
- 음성 관련: 미디어젠(음성·영상 생성), ETRI(멀티모달 AI에 음성 포함), MBC(미디어 콘텐츠 음성 적용) 등 3개 기관
이는 제조·미디어 콘텐츠에 특화된 NC AI 컨소시엄 성격 때문이다.
NC AI : VARCO
Via AI, Realize your Creativity and Originality
AI를 통해 당신의 독창성을 실현하라는 의미를 담고 있는 VARCO 모델에 대해서 본격적으로 알아보겠다.
VARCO는 크게는 3 분야, 세부적으로는 총 11개의 모델로 구성되어 있다.
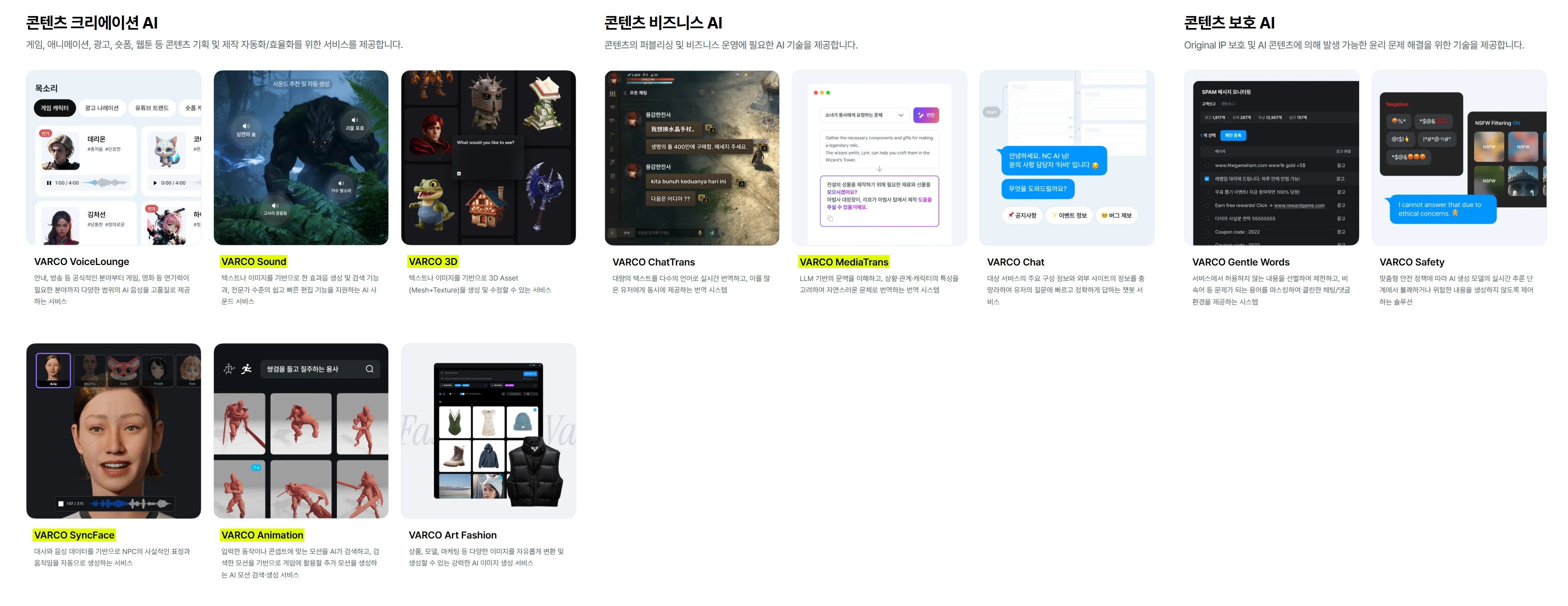
여기서 하이라이트를 친 5개 모델(Sound / 3D / SyncFace / Animation / MediaTrans)은 내가 판단하기에 유미한 것들이고, 나머지 번역, 채팅, 이미지 생성, 패션 생성, 필터링 같은 범용 분야는 아무리 삽질해도 글로벌 빅테크 모델 하위호환일 뿐, 차별성이 희박하다고 본다.
국내 기업 입장에서야 데이터 보안·국내 규제 대응, 한글 특화 지원 등의 이유로 선택할 수는 있겠으나, 일반 개인에게는 "굳이 내가 엔씨소프트 게임을 플레이하지 않는 이상 쓸 일은 없을 것 같은데?" 싶을 것이니 B2B에 훨씬 가깝다.
VARCO 3D : 7월 29일 베타 오픈
지난 7월 11일에 공식 유튜브 채널에 올라온 영상이다. (놀랍게도 작성일 기준으로 이게 가장 최신이다.)
영상 속에서도 7월 29일부터 3D 베타 서비스를 오픈한다고 적혀있다.

VARXCO 3D의 기본 화면이다. 구글로 최초 로그인하면 우측 상단에 보이는 것처럼 2000 크레딧을 제공해 준다.
테스트는 극악 난이도부터 시작하여, 점차 낮추는 식으로 진행하겠다.
높은 난이도의 기준은 T23D가 아닌 I23D 적용이다.
보통 Text to Image, to Video, to 3D는 결과물이 대체적으로 뛰어나다. 참고 이미지가 없으니 기존 학습 데이터를 기반으로 생성을 하면 되기 때문이다.
반면 Image to Image, to video, to 3D는 매번 학습되지 않은 새로운 데이터가 추가되므로, 결과물의 퀄리티가 텍스트 기반보다 전반적으로 떨어질 수밖에 없다.
참고로 T23D는 100크레딧, I23D는 200크레딧이 소모된다.
성능 테스트
난이도 극악 : 짱구
[Week2-1] NSFW 규제 / Hitem3D / Kontext Dev를 더 스마트하게 사용하는 법
🤗Hugging Face : NSFW 규제 시작드디어 Hugging Face에서 '성인물 규제'가 시작되었다.항상 어떠한 신기술이 등장하면 그것을 악용하려는 사람들이 많다. 과거 '딥페이크'때처럼 최근 'Flux'도 인물의 표
mapsycoy.tistory.com
예전 2주 차 포스팅에서 싱가포르의 Hitem3D를 테스트해 본 적이 있다. 그때도 짱구 이미지를 갖고 테스트를 진행했었는데, 실패했다. 과연 한국의 VARCO는 해낼 수 있을까?

윽... 정말 끔찍한 결과물이 나왔다.

그래도 나는 '짱구 한정'으로는 Hitem3D보다 VARCO 3D가 더 낫다는 판단이다.
왜냐하면 Hitem은 아예 3D로 변환하려는 노력 자체를 하지 않은 반면, VARCO는 어떻게든 메쉬를 구성해 보려 노력한 흔적이라도 보이기 때문이다.
난이도 상 : 스펀지밥 인형
난이도 상의 기준은 Depths 확인 목적이 크다.
내가 첨부한 이미지의 깊이감을 AI가 얼마나 잘 인식해서 결과물을 생성하는지를 중심으로 보겠다.

와우! 팔이 4개가 되었고, 몸이 많이 두꺼워지고, 발까지 몸에 붙어버렸다.
Depths 해석 기준으로는 완전 실패지만, 그래도 텍스처링은 전반적으로 원본 이미지의 형태와 질감에 충실하게 따르고 있음을 확인할 수 있다.
난이도 중상 : 헤카림
NC AI는 게임과 관련된 학습 데이터가 분명 많이 쌓여있을 것이기에 인지도가 높은 게임 캐릭터로 테스트를 진행해보고자 한다. 다만, 난이도 중상인만큼 사람이 아닌 반인반수, 헤카림의 독특한 포즈를 테스트 이미지로 사용하였다.

이럴 수가... 예상과는 달리, 되려 난이도 상의 스펀지밥 인형보다 인식율이 떨어지고, 심지어 메쉬가 찢어져 있기까지 했다.
음, 하지만 이건 원본 일러스트의 포즈가 너무나 불진철하다는 문제일 수도 있겠다는 생각이다.
그래서 다른 포즈로 재시도해보기로 하였고, 더 나아가 아예 직접 헤카림 3D 모델의 스샷을 누끼 따서 그린스크린 위에 얹어줬다.
이 정도 떠먹여 줬으면 잘하겠지 싶었는데...

아주 부담스러운 엉덩이가 두드러진 결과물이 나왔다.
엔씨소프트 게임에 원래 헤카림 같은 '켄타우로스' 캐릭터가 없나? 좀 이따 텍스트 프롬프팅에서 테스트해 보겠다.
난이도 중 : 군주
난이도 중에서는 엔씨의 대표 게임 속 대표 캐릭터인 리니지 군주 일러스트를 적용해 보겠다.

외모 디버프가 너무 강하게 적용된 건 아닌지.. 그저 아쉬운 결과이다.
Img23D 테스트는 이만 마치고, 난이도 하 : Text23D로 넘어가겠다.
난이도 하 : 텍스트 프롬프팅
텍스트로는 켄타우로스 캐릭터가 가능할 확률이 매우 높으니 바로 진행하겠다.
내가 사용한 프롬프트는 다음과 같다.
A centaur warrior with the upper body of a muscular human and the lower body of a powerful horse. Wearing dark, battle-worn armor with glowing runes, holding a large halberd. Long glowing mane and tail, demonic helmet with glowing eyes.
위 프롬프트를 입력하자 AI가 다음과 같이 4개의 이미지를 제안해 줬다.

이 중 내가 택한 것은 3번 이미지이다.
아니, 잠만 이러면 처음 프롬프팅에서 100 크레딧이 소모되고, 이미지 선택에서 200 크레딧이 추가로 소모되니 결론적으로는 이미지보다 텍스트 프롬프팅이 더 비싸다.
아무튼 3번 이미지를 적용한 결과물은 다음과 같다.

역시 텍스트 프롬프팅 기반은 결과가 준수한 편이다.
이제 크레딧이 딱 700개 남은 김에 2번만 더 생성해 보겠다.
이번에는 '경복궁'으로, 프롬프트는 다음과 같다.
A Gyeongbokgung Palace in Seoul, South Korea. Traditional Korean architecture with curved tiled roofs, wooden beams, and colorful dancheong patterns. Wide stone courtyard, main gate with watchtowers, and surrounding palace walls.

꽤나 놀라운 결과물이다. 우리나라에서 개발한 AI라 그런지 중국 느낌보다는 확실히 한국 궁궐의 느낌이 더 강하다.
나는 아치형 구조가 마음에 들어 3번 이미지를 선택했다.

아... 근데 메쉬 상태가 영 좋지 않다.
이미지를 크게 들여다보면 특히 지붕 쪽 메쉬가 많이 뭉개져있다. 아무래도 규모가 큰 Environment 생성까지는 아직 무리인 듯하다.
마지막은 자유주제로 가보겠다.
"엔씨소프트 게임을 대표하는 캐릭터를 생성해 줘."
A game character inspired by iconic NCSoft titles such as Lineage, Blade & Soul, and Aion.
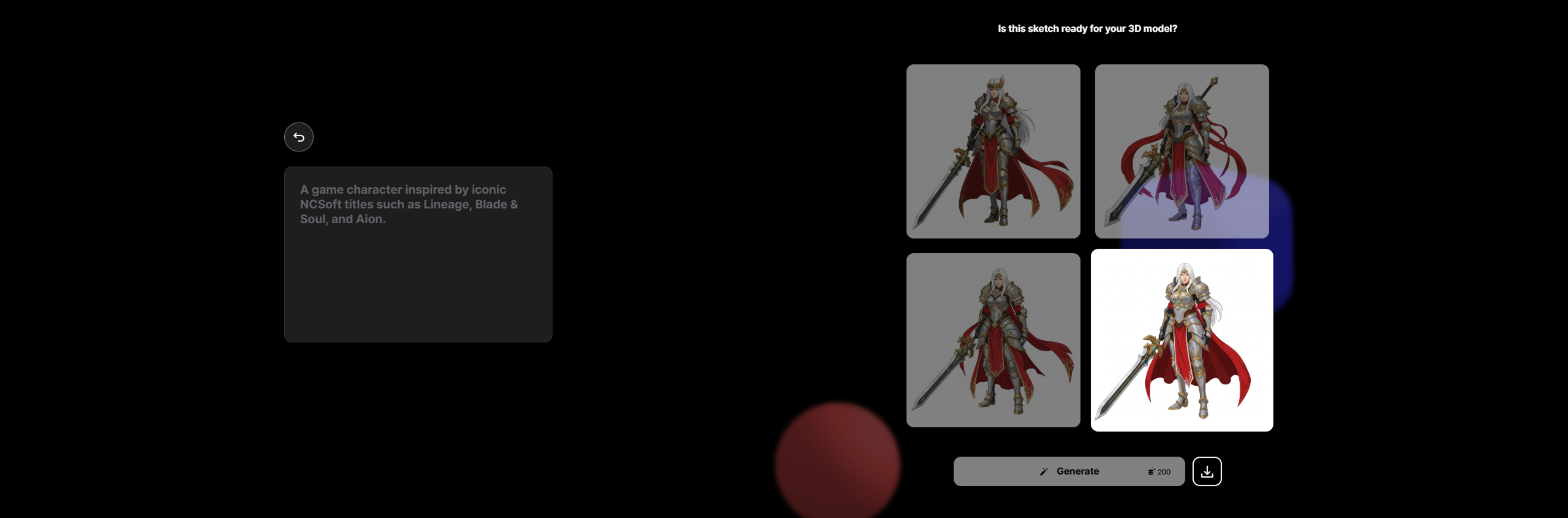
잔다르크 같은 여성 기사가 대표 캐릭터로 생각되나 보다.
개인적으로 4번 이미지가 가장 군더더기 없이 깔끔하여 선택하였다.
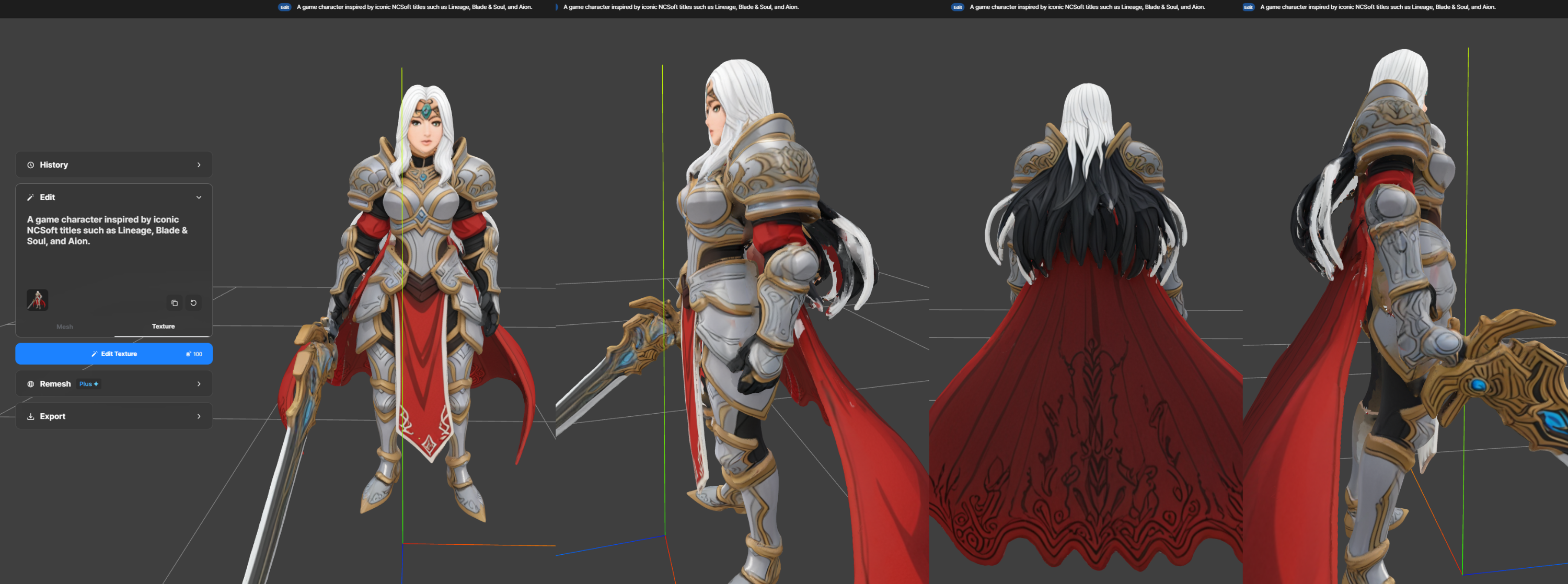
어? 뭔가 이상하다. 상당히 많은 부분들이 왜곡되어 있는데... 특히 얼굴과 검을 들고 있는 오른손 부분이 유독 심하다.

텍스처를 제거한 메쉬 상태로만 보면 이목구비 자체가 생략되어 있다. 뿐만 아니라 모든 게 파츠 단위가 아니라 한 덩이로 묶여있다.. 이러면 엔씨소프트에서 추구하는 AAA급 MMORPG에서는 배경에 아주 작게 등장하는 비중 없는 NPC 캐릭터로도 사용이 꺼려질 것이다. (이런 줄 알았으면 아까 켄타우로스 캐릭터도 메쉬 상태로 뜯어볼 걸)
3D 테스트 결과
3D 테스트 결과는 다음과 같이 정리해 볼 수 있겠다.
우선 강점이다.
- 프롬프트 적용 시 생성되는 스타일이 한국적이다.
- 메쉬 상태에 비하면 UV매핑은 괜찮다.
- 4가지 이미지 바리에이션을 제공해 준다.
그리고 약점으로는
- 메쉬가 엉망이다.
- 그렇다고 로우폴리라고 볼 수도 없다.
- 노멀맵 세분화가 없다.
이걸 일일이 다시 스컬핑하고 리토폴로지 하느니 처음부터 직접 만드는 것이 훨씬 나을 것이다.
전반적으로 퀄리티가 많이 떨어지는 것이 베타라고는 하지만... 아쉬움은 많다.
3D를 제외한 나머지 하이라이트는 테스트 불가
*참고로 VARCO 패션 쪽은 문의하면 오픈해 준다 하더라.
근데 어차피 기업고객이 아니면 못 쓴다.

이건 23년도 소개영상 업로드 당시, NC AI가 자체 개발 모델을 올려두었던 aws marketplace이다.
이곳에는 내가 하이라이트한 모델이 존재하지 않을뿐더러, 가장 상단의 최신 모델인 Llama-VARCO-8B-Instruct는 24년 7월 모델로 업데이트조차 하지 않고 있는 사실상 '버려진 페이지'이다.
그렇다면 HuggingFace 상황은 어떨까?

현재 HuggingFace 커뮤니티에 오픈 소스로 나와있는 VARCO 모델은 오직 VISION 하나뿐이다.🫤
가장 최근에 업데이트된 NCSOFT/VARCO-VISION-2.0-1.7B-OCR 기술서를 한번 봐보겠다.

이런 기능이 있다고 한다.
파파고 AI 이미지 번역에 비하면 하위 호환이라 하기에도 애매하다.
어쨌든 규모가 1.7B라는 점에서는 경쟁력이 아예 없지는 않을 것 같고, 역시나 기술서에서도 그 부분을 장점으로 내세우고 있다.
While VARCO-VISION-2.0-14B demonstrates strong OCR capabilities as part of its broader multimodal reasoning skills, deploying such a large model for single-task use cases can be computationally inefficient. VARCO-VISION-2.0-1.7B-OCR addresses this with a task-optimized design that retains high accuracy while significantly reducing resource requirements, making it ideal for real-time or resource-constrained applications.
서술된 내용처럼 실제로 낮은 파라미터 수에 비해 그 정확도는 매우 높은 것으로 보인다.

그리고 이건 좀 더 높은 파라미터가 적용된 14B 모델 소개 이미지이다.
14B도 경량화된 SLM(1B~20B) 축에 속하는데, 이 정도 퀄리티면 최적화가 잘 되어있다고 볼 수 있겠다.
근데 좌측 상단, 그리고 우측 하단 블록 속 AI의 답변문을 자세히 읽어보면 옥에 티가 있다.
김밥 레시피에 파를 넣는다던가, 저 유부 우동 국물을 AI가 '디핑 소스'로 해석하는 걸 볼 수 있다.
물론 파김밥이라는게 존재는 하지만, 일반적인 레시피라고 볼 수는 없다. 솔직히 참치도 그렇다. 보통은 햄이 들어가지, 외국인이 보면 우리나라 김밥에는 무조건 파와 참치가 들어가는 줄 알 거 아니냐.
게다가 실제로 첨부된 김밥 이미지는 돈가스 김밥이다. 시금치가 파로 해석된 것은 유사성으로 인한 실수라 볼 수 있지만, 돈가스가 참치로 해석되었으니, 이건 편향된 데이터라고 볼 수 있다. (아무래도 개발자가 참치 김밥을 많이 좋아하는 듯)
보통 이런 허점은 기술 소개 이미지에 잘 넣지 않는데, NC AI 개발진이 지나치게 솔직한 것인지 아니면 실수한 것인지는 모르겠다.
오늘의 결론
이쯤 되니, 초반에 업계에서 NC AI의 Top 5 선정결과가 예상 외라는 반응을 보였다는 것이.. 이러한 다소 아쉬운 이유 때문인 것은 아닌지 조심스럽게 추측해 본다.
이거 약간 펄어비스 도깨비 '베이퍼웨어 의혹'과 비슷한 냄새가 나는데.. 기분 탓이길 바란다.
어쩌면 경쟁사의 견제를 피하려는 고도화된 전략일 수도 있다. 최대한 숨죽이고 있다가 종단에 허를 찌르려는..
지금까지 다 농이었고, 아직 공개되지 않은 모델들이 더 많으니 앞으로 많은 부분 개선되지 않을까 한다.
*썸네일 출처 : https://nc-ai.com/en
- 현재 엔씨소프트 CEO이자 CCO인 김택진 대표는 과거 아래아한글을 공동개발하였고, 버전 1이 출시된 이후 1990년 10월에 한글과컴퓨터가 설립되었다.↩
- 현재 제6대 과기정통부 장관 배경훈은 지난 6월까지만 하더라도 LG AI 연구원장이었다.↩
'생성형 AI' 카테고리의 다른 글
| [week12] GPT 튜닝 (+앞으로의 방향성) (0) | 2025.09.20 |
|---|---|
| [week9-2] Qwen-Image-Edit (FLUX.1 Kontext와 차이점) (0) | 2025.08.26 |
| [week6] Wan2.2 TI2V / Ideogram Character 살펴보기 (+문제점) (0) | 2025.08.03 |
| [week5-2] 4가지 Bleeding 현상 (Poisoning/Distraction/Confusion/Clash) (0) | 2025.07.31 |
| [week4-2] 유럽권을 선도(?)하는 프랑스의 Mistral AI (0) | 2025.07.23 |